Elastic depth
Standard looped models are usually trained at one fixed unroll depth. LoopFormer is trained to operate across variable-length trajectories.
LoopFormer trains looped Transformers on variable-length trajectories so the same model can reason under different compute budgets, stay stable across shortcut schedules, and keep improving as budget grows.
Method snapshot
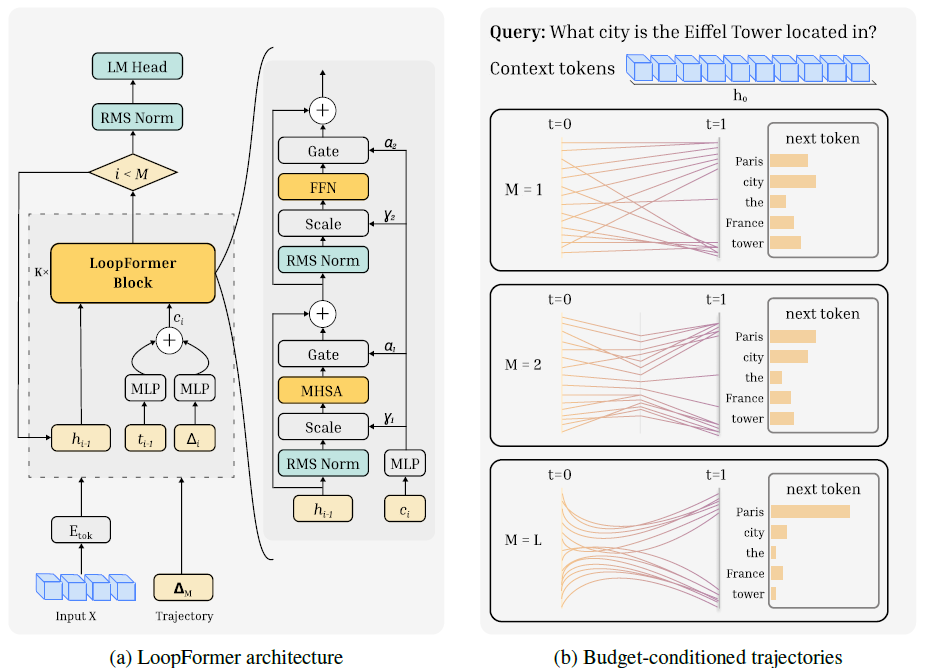
Each loop step sees both internal time t and step size Δt.
Short routes are aligned to full routes so reduced-budget runs remain informative.
Choose the compute budget at test time without retraining the model.
Overview
Standard looped models are usually trained at one fixed unroll depth. LoopFormer is trained to operate across variable-length trajectories.
Coarser schedules can approximate finer ones, letting the model take larger jumps without drifting or collapsing.
Inference can be adapted to a chosen budget, trading cost and quality smoothly instead of being locked to a single setting.
Looped (recurrent) Transformers are an efficient alternative to deep non-shared stacks, but in practice they are almost always trained and evaluated with a fixed number of unrolls. As a result, performance often collapses when running at shorter or longer depths—making looped models far less compute-elastic than they should be.
LoopFormer treats iterative refinement as a trajectory in representation space. Each loop step is conditioned on internal time t and step size Δt, so coarser schedules can mimic finer-grained ones with fewer steps.
Training uses a shortcut-consistency objective that aligns shorter routes to the final representation of the full route. At inference time, users choose a budget M ≤ L and a schedule, and the model scales gracefully with compute—without retraining.

Results
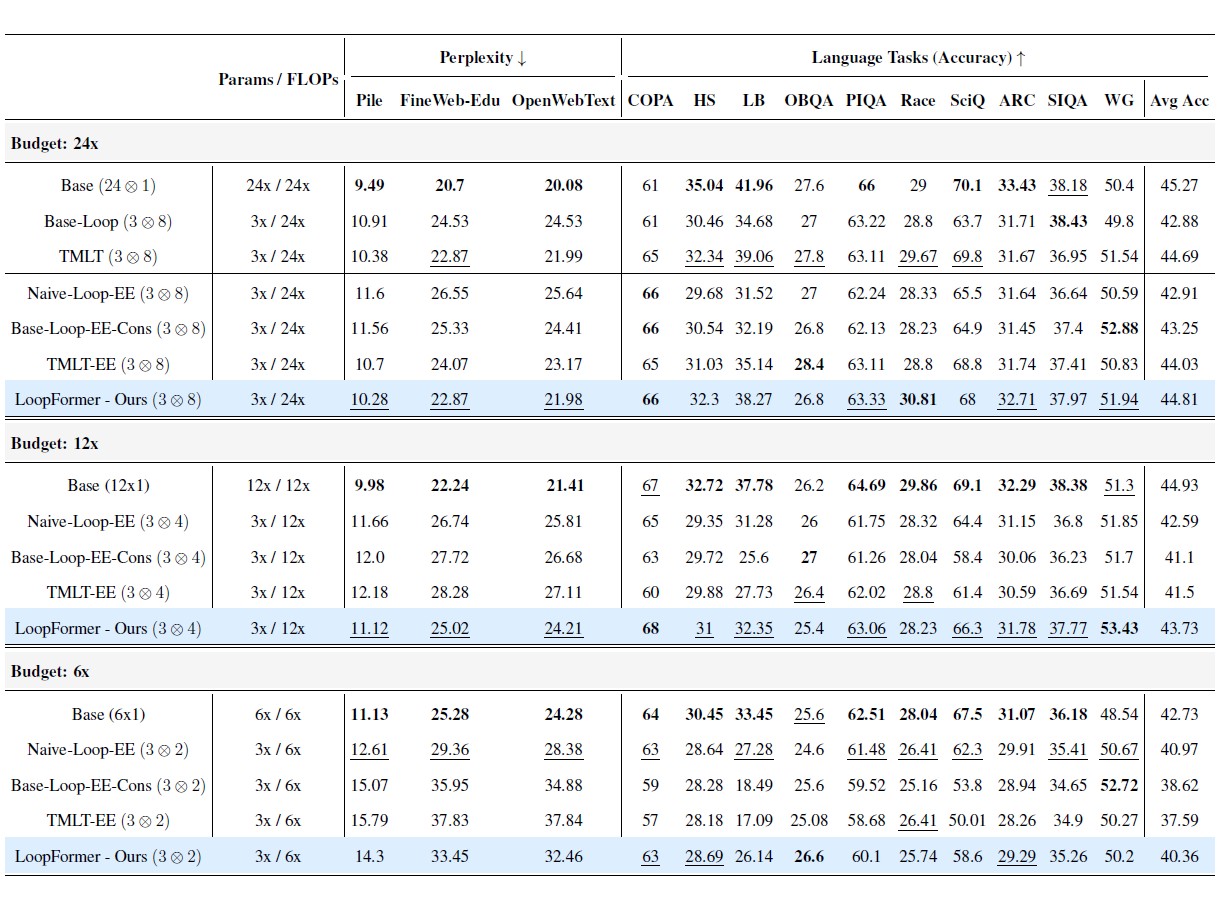
LoopFormer is compared against vanilla non-looped Transformers, fixed-depth looped models, and adaptive early-exit baselines. The main takeaway is simple: making looped depth explicitly budget-aware improves the quality/compute trade-off rather than only the peak setting.
Analysis
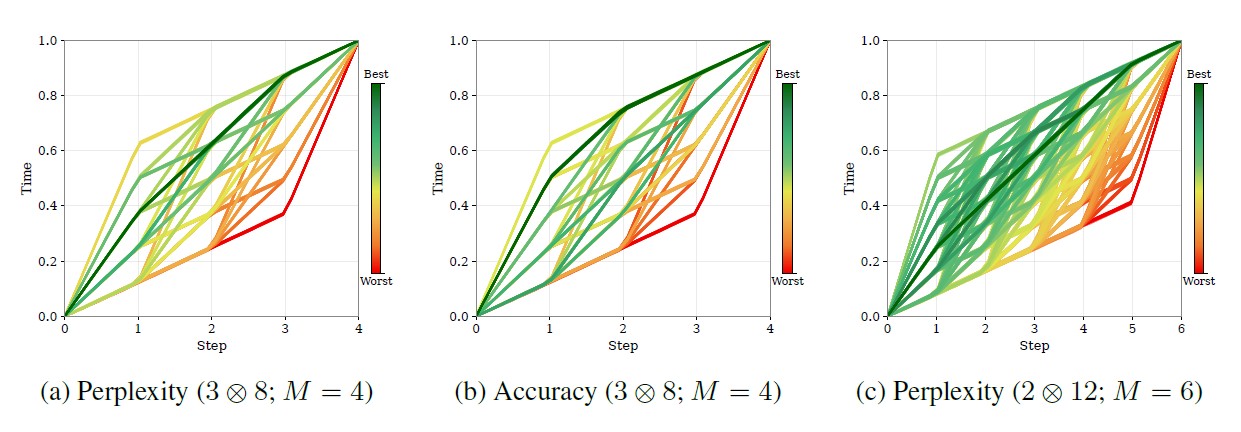
Under similar compute budgets, LoopFormer remains competitive while varying the number of blocks and loop steps. The plots below highlight two complementary views: language modeling quality through perplexity, and zero-shot reasoning performance across 10 language reasoning benchmarks.
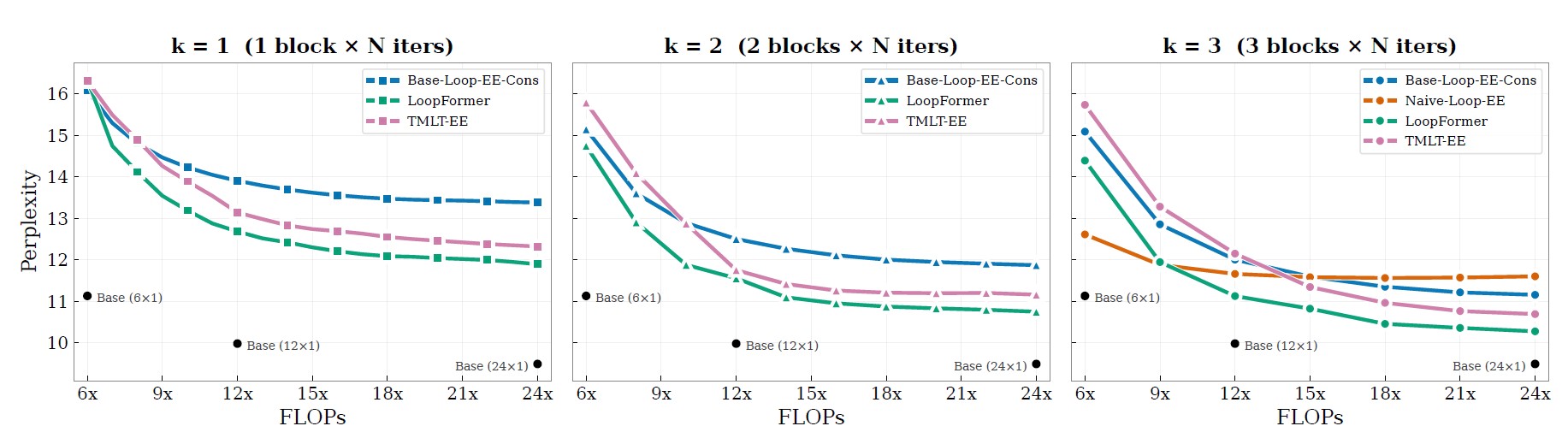
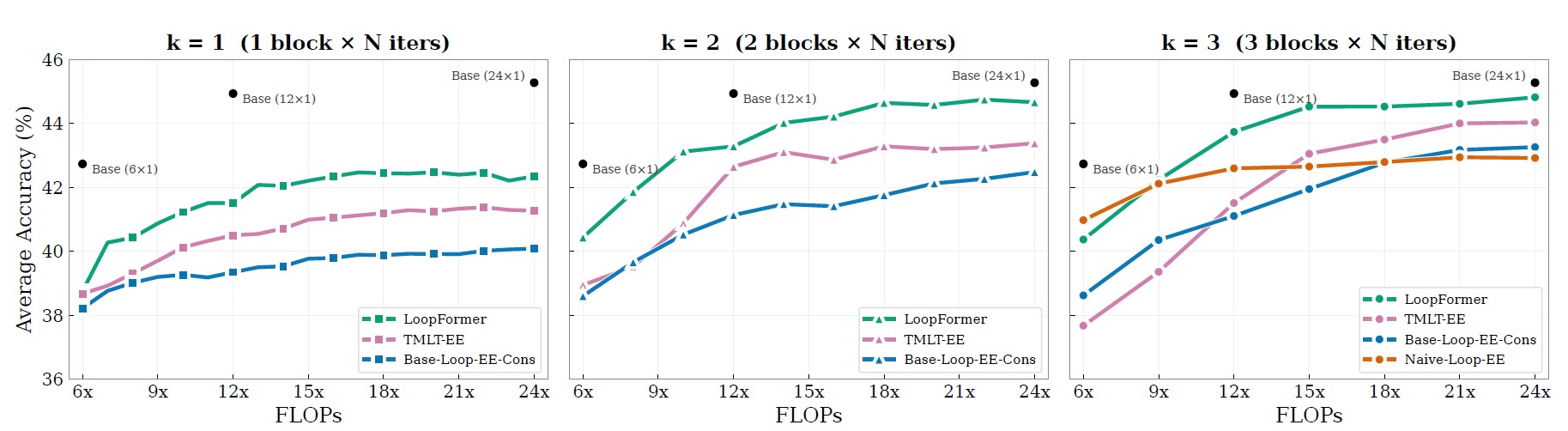
A core idea in LoopFormer is that iterative refinement follows a trajectory in representation space. Different shortcut schedules produce different trade-offs: the route that minimizes perplexity is not always the one that maximizes reasoning accuracy.
This makes trajectory design a real control knob for deployment. LoopFormer exposes that knob directly, instead of hiding it behind a single fixed-depth operating point.
Citation
@inproceedings{jeddi2026loopformer,
title = {LoopFormer: Elastic-Depth Looped Transformers for Latent Reasoning via Shortcut Modulation},
author = {Jeddi, Ahmadreza and Ciccone, Marco and Taati, Babak},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2026},
url = {https://openreview.net/forum?id=RzYXb5YWBs}
}